Re-imagining Miller's Pyramid
India's 700+ medical colleges are producing doctors for a world that no longer exists. It is time to bury a 35-year-old framework and replace it with one that puts AI as the accountable conscience.
In 1990, George Miller drew a triangle. Four levels — Knows, Knows How, Shows How, Does — and in doing so, gave medical education its most enduring metaphor. Generations of faculty development workshops have been run in its name. Examination blueprints have been justified by its geometry. And yet, Miller's pyramid was built for a world of textbooks, bedside teaching, and memory as the primary repository of clinical knowledge. That world is gone. The question is not whether to update the pyramid. The question is whether we have the intellectual courage and resources to do it and whether India, with its extraordinary scale, its radical inequities, and its extraordinary digital infrastructure ambitions, might be the place where it actually happens…

What Miller Got Right, and What He Could Not Have Known
Miller’s genius was to shift assessment’s gaze from the declarative to the performative. Before his framework, medical examinations were overwhelmingly tests of recall, the MCQ as the gold standard of knowledge. Miller argued that knowing facts was the least interesting thing a clinician did. The pyramid’s elegance was its direction of travel: upward, from knowing toward doing, from the abstract toward the real. This was radical in 1990, and it remains pedagogically sound.

What Miller could not have anticipated:
• That AI systems would generate structured clinical outputs almost indistinguishable from expert reasoning
• That the individual human mind would cease to be the primary knowledge retrieval system
• That the most dangerous failure point would be the absent roof of his pyramid: no accountability loop above ‘Does’
The Three Broken Assumptions
Miller’s framework rests on three assumptions that no longer hold in the Indian or broader LMIC context:
1. Assessors are reliable and consistent — in reality, India’s faculty-to-student ratios and assessment conditions produce significant inter-rater variability that goes unmeasured.
2. Performance reflects reasoning — AI now allows polished, structured outputs to be produced without the reasoning that should underlie them.
3. Doing automatically implies accountability — there is no mechanism in the current framework for connecting what a clinician does to what happens to the patient afterward.
The Indian Constraint: Why This Is Not Optional
In high-resource systems, institutional redundancy partially compensates for individual competency gaps. In India, individual judgment is often the only safety net. The Modern Medicine practioner practicing in a primary health centre in rural Chhattisgarh operates with limited diagnostics, interrupted supply chains, no specialist backup, and intense medico-legal exposure. The pyramid must be rebuilt for this reality, not for the simulation lab.
India’s scale amplifies the stakes: 700+ medical colleges, approximately 1,25,000 MBBS graduates annually, radical variation in training quality between institutions, and a health system undergoing rapid digital transformation through initiatives like the Ayushman Bharat Digital Mission. Whatever framework India builds will become a template for a significant portion of the world.
The Central Question
If AI can produce answers that look like competence, what exactly are we certifying? And if we do not redesign the apex of the pyramid, are we producing clinicians who can perform or clinicians who can be accountable for what they do?
The Proposed Architecture
The Augmented Competency Architecture (ACA)
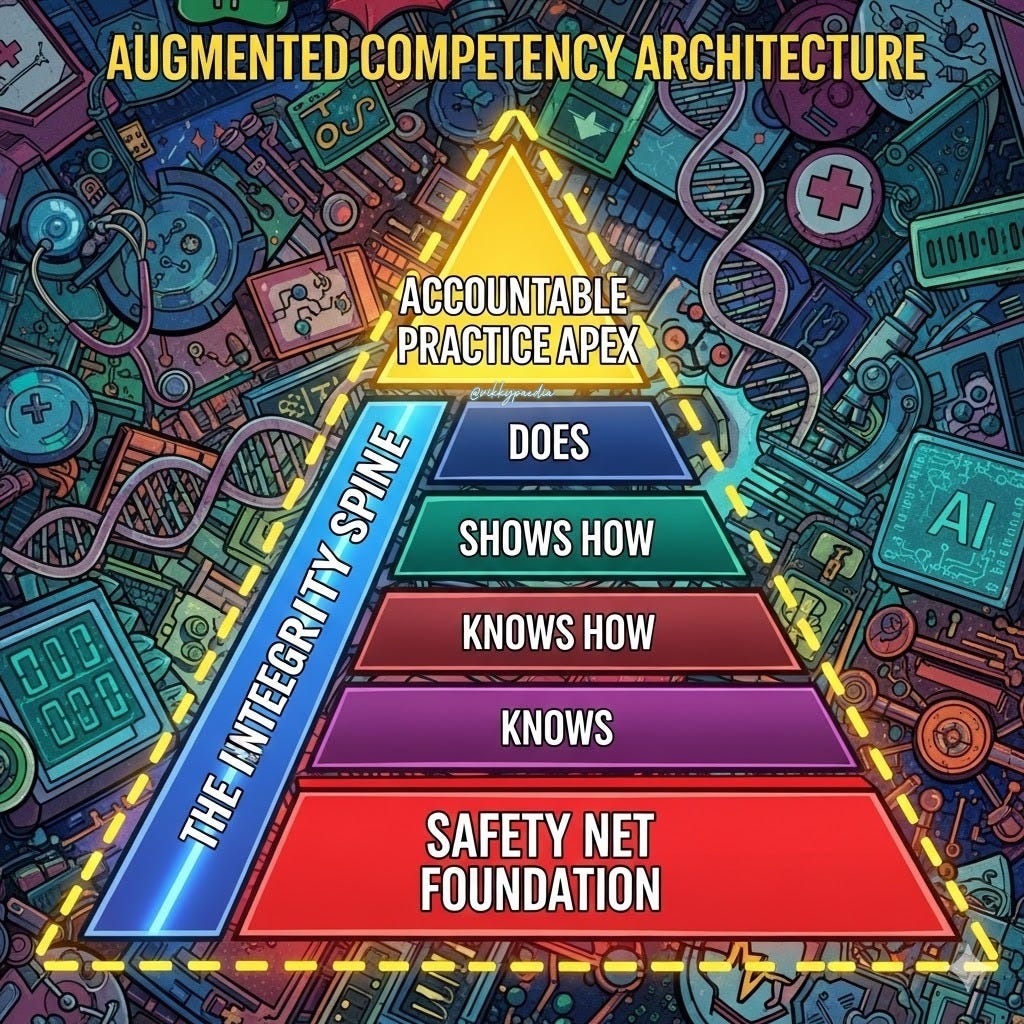
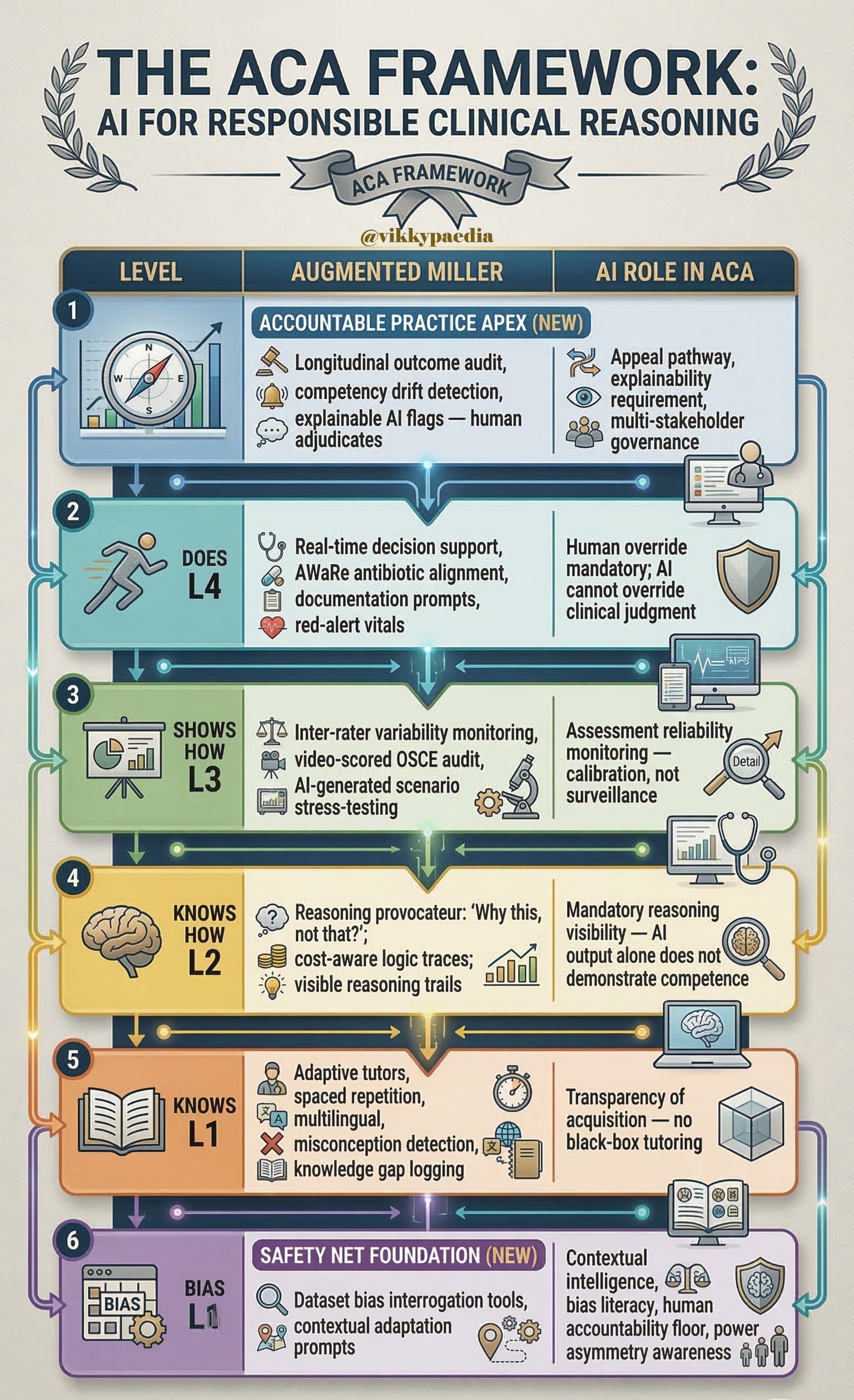
The ACA retains Miller’s four levels and augments each with a defined AI role and a defined safety net mechanism. It adds two new structural elements: an Accountable Practice Apex above ‘Does’, and a Safety Net Foundation below ‘Knows’. Running vertically through all levels is the Integrity Spine — the thread that connects the whole into an accountable system.
html link : https://claude.ai/public/artifacts/3748954e-a873-4f0b-beb4-db93c778d8f0
Framework at a Glance
The Integrity Spine
The Integrity Spine is not a level — it is a vertical requirement running through all levels. Without it, each AI intervention is isolated and gameable. With it, the pyramid becomes a coherent accountability system.
The Spine has three components:
• Provenance — where did this answer, decision, or action originate? Was it AI-generated? Was it verified?
• Reasoning Trace — what was the logical path that led to this decision? Is it visible, teachable, and contestable?
• Outcome Linkage — what happened to the patient, student, or case after the decision was made? Is this fed back into the learner’s profile?
If any of these three are missing at any level, the framework collapses into the same assessment theatre Miller was trying to escape in 1990.
The Safety Net Foundation
The foundation is not a curriculum module. It is a set of structural commitments that must permeate every level of training. For India and LMICs, four elements are non-negotiable:
1. Contextual Intelligence — the competency to interrogate AI output against the specific patient, infrastructure, and resource reality of the clinical encounter.
2. Dataset Bias Literacy — the ability to ask: ‘What population was this model trained on, and does it look like my patient?’ This is a clinical safety skill, as fundamental as knowing drug contraindications. Most major AI medical tools are trained on Western, high-income datasets; their performance on patients in rural India is largely untested.
3. Human Accountability Floor — no AI system in this architecture displaces the clinician’s accountability. This must be institutionally and legislatively clear before the technology makes the decision by default.
4. Power Asymmetry Awareness — AI can amplify or reduce India’s significant doctor-patient information asymmetry. Training must address how AI is communicated to patients, in their language, at their health literacy level, with genuine consent.
The Governance Perimeter
Wrapping the entire architecture is a governance structure without which the framework cannot function. Key questions requiring institutional and policy resolution:
• Who owns the data generated by the AI audit layer — the learner, the institution, the regulator, the patient?
• Who audits the AI systems themselves — for bias, for drift, for alignment with local populations?
• Who updates protocols when evidence changes?
• How are disputes resolved when AI flags a pattern that a clinician contests?
• How is the architecture protected from gaming — the same gaming instinct that has made some Indian accreditation processes documentation exercises rather than quality mechanisms?
Design Principle
The governance architecture must assume that gaming is possible and design against it. Cross-linking prescription patterns with resistance trends, billing with outcomes, and discharge notes with readmission timing creates a system that cannot easily be gamed without the fraud becoming visible.
The India Case in Full
The Structural Reality
India’s medical education system is characterised by:
• 700+ medical colleges with radical variation in quality, infrastructure, and faculty competence
• NMC CBME mandate (2019) — well-intentioned, unevenly implemented
• Faculty-to-student ratios that make individual mentoring largely impossible in many institutions
• Assessment systems that remain heavily examination-oriented with limited authentic workplace-based assessment
• A digital infrastructure ambition — Ayushman Bharat Digital Mission, National Health Stack — that creates the conditions for the ACA’s accountability layer to be technically feasible
The Equalisation Opportunity — and Its Risks
AI arrives with a genuine equalisation offer: an adaptive tutor does not know whether the student is in an AIIMS campus or a poorly-resourced district college. This potential is real. But three risks must be named explicitly:
1. Infrastructure inequality — institutions without reliable electricity, bandwidth, or devices cannot participate in an AI-augmented framework without supplementary provision. The framework must specify minimum viable infrastructure requirements.
2. Dataset colonialism — AI tools trained on Western patient data may actively mislead clinicians treating Indian populations. Tropical disease presentations, nutritional deficiency patterns, and drug response variation in Indian populations are underrepresented in most major training datasets.
3. Compliance theatre — India already has experience with accreditation processes that reward documentation over transformation. If AI becomes another compliance layer, generating dashboards without integrity; the framework will produce a more sophisticated version of the same problem.
Connection to Existing Policy Instruments
The ACA is not a framework requiring entirely new infrastructure. It connects to instruments already in development:
• ABDM health records infrastructure : provides the longitudinal data substrate for the Accountable Practice Apex
• NMC CBME core clinical training requirements : provides the competency anchors to which AI audit can be linked
• AWaRe antibiotic framework : provides a concrete example of AI-supported decision guidance at the ‘Does’ level with measurable outcome linkage
• National Pharmacovigilance Programme : provides an existing outcome-linkage mechanism that the ACA’s reasoning trace can feed into
Beyond Medicine
The Cross-Professional Claim
The structural problem the ACA addresses is not unique to medicine.
Every professional formation system faces the same question: if AI can generate competent-looking output, what is human competence?
The answer across all professions is identical — it is judgment, accountability, and consequence awareness.

The Equity Argument
The Paradox of LMIC Innovation
Paradoxically, resource-constrained settings may be better positioned to innovate in this framework than high-income systems. The reason is that constraints force clarity. Designing the ACA assuming limited diagnostics, variable connectivity, low-cost devices, and high patient load produces a framework that is globally resilient, not one that requires downward adaptation from a high-income default.
High-income systems can adopt this framework. But its architecture must be designed upward from constraint, not downward from abundance…!
The Faculty Question
Neither our earlier framework nor the parallel document reviewed adequately resolves the question of the faculty member’s role in an AI-augmented system. This is the most pressing unresolved issue in the framework, and it deserves a dedicated section in any published version.
If AI is the tutor at Knows, the reasoning provocateur at Knows How, the calibration engine at Shows How, the decision support at Does, and the longitudinal auditor above; what is the teacher’s irreducible function? The answer cannot simply be ‘judgment modelling’ if faculty have not themselves developed the metacognitive habits the new pyramid demands of students. A generation of learners whose AI-literacy exceeds their teachers’ is not a hypothetical in India. It is a present reality in some institutions…!
The framework requires a parallel faculty development architecture, not a separate workshop series, but an integrated understanding that faculty are also being audited, calibrated, and held accountable within the same system.
The Debates That Must Be Had
This framework is offered as a provocation, not a settled conclusion. The following questions are deliberately left open for community debate:

and Finally…
Miller moved professional education from knowledge to performance. The AI era demands a further move: from performance to accountable practice. The Augmented Competency Architecture proposed here is not a rejection of Miller’s contribution. It is its structural completion for a world he could not have anticipated.
The pyramid needs a roof — the Accountable Practice Apex. It needs a spine — Provenance, Reasoning Trace, Outcome Linkage running through every level. It needs a foundation that is explicit about what assumptions it is making and what populations it is designed to serve. And it needs a governance perimeter that ensures AI strengthens evidence without becoming invisible power.
India has the scale, the urgency, the digital infrastructure ambition, and the moral stakes to build this framework first, and to build it right. The alternative, grafting AI onto existing assessment structures; will not improve competence. It will industrialise the illusion of it.
In countries where the margin for error is thin and families trust the white coat deeply, that is not an academic risk. It is a moral one.
Key References & Further Reading
• Miller, G.E. (1990). The assessment of clinical skills/competence/performance. Academic Medicine, 65(9), S63–S67.
• National Medical Commission. (2019). Competency-Based Medical Education Curriculum for MBBS. NMC India.
• Topol, E.J. (2019). High-performance medicine: the convergence of human and artificial intelligence. Nature Medicine, 25, 44–56.
• Meskó, B. & Topol, E.J. (2023). The imperative for regulatory oversight of large language models in healthcare. npj Digital Medicine, 6, 120.
A little complicated and dry - but surely very important
Very interesting !